Pandas
<기능 요약 정리>
- Data frame 자료형 만들기
- Series 자료형 만들기
- 기술통계
- NA값 처리
- 엑셀 파일 불러오기 (파일 형식: xlsx, csv, Pandas_dataframe(pickle), json; txt도 가능)
오늘은 엑셀 파일 불러오기를 간단히 살펴보자!
5. 엑셀 파일 불러오기
5.1 csv형식의 엑셀 파일 불러오기
pd.read_csv("파일경로명.파일명.csv")
※단, 경로명의 \을 전부 /로 교체해주어야 한다.
#엑셀 파일 중 확장자명이 .csv인 파일 불러오기
import pandas as pd
train = pd.read_csv("D:/thon/data/kaggle/titanic_ex/train.csv")
train.head()

만약 여기서 주피터 노트북을 사용하고, 불러오고자 하는 데이터가 기본 경로에 포함되어있다면,
'./'로 기본경로를 생략해줄 수 있다.
내 컴퓨터의 경우 기본경로가 D드라이브의 thon폴더이므로 이 부분은 ./로 생략하고 불러올 수 있다.
#./활용
test = pd.read_csv("./data/kaggle/titanic_ex/test.csv")
test.head()

pd.read_csv의 몇 가지 옵션
1. header = True or None : True -> 칼럼명 출력 ||| None -> 칼럼명 없이 인덱스로 대체
#header = None 옵션
#칼럼명이 출력되지 않음
test_without_header = pd.read_csv("./data/kaggle/titanic_ex/test.csv", header = None)
test_without_header.head()

2. index_col = '칼럼' : 한 칼럼을 인덱스로 지정
#index_col = '칼럼' 옵션
#데이터의 칼럼을 인덱스로 지정
test_index = pd.read_csv("./data/kaggle/titanic_ex/test.csv", index_col = 'PassengerId')
test_index.head()

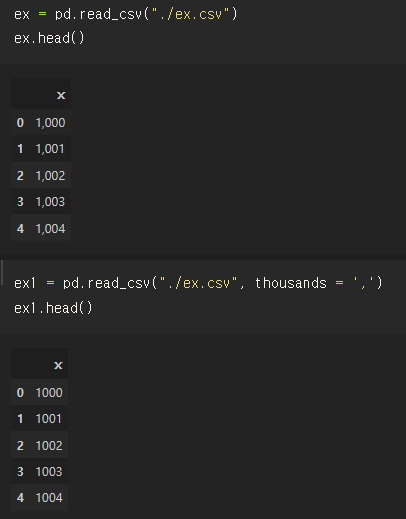
3. thousands = ',' : 천 단위를 쉼표로 분리한 데이터의 쉼표 제거
전처리 과정 초반에 csv파일에 입력된 값들이 쉼표를 포함하고 있어서 int형으로 바뀌지 않는 문제에 봉착했던 적이 있다.
이 문제는 데이터를 불러올 때 아예 쉼표 값을 제거하여 불러옴으로써 해결할 수 있었다.
그 옵션이 바로 thousands = ',' 옵션이다.
작성한 데이터 csv파일로 내보내기 (.to_csv("경로"))
이제 수정한 파일을 csv 파일형식으로 내보내보자.
아까 불러온 test.csv 파일의 몇 개 칼럼을 삭제하고 내보내보자.

### 데이터명.to_csv("경로/파일명지정.csv") ###
test.to_csv('./test_out.csv')

기본적인 불러오기와 내보내기를 살펴보았다.
하지만 실제로 분석용 파일을 내보내거나 불러오는 과정에서 파일 encoding 문제로 오류가 뜨는 경우도 많고, 뭔가 알 수 없는 이유로 출력이 안되는 일도 있다.
이런 사소한 오류들은 나중에 실제로 겪으면 그 해결책을 공유하면서 해결해보고자 한다.



