Pandas
<기능 요약 정리>
- Data frame 자료형 만들기
- Series 자료형 만들기
- 기술통계
- NA값 처리
- 엑셀 파일 불러오기 (파일 형식: xlsx, csv, Pandas_dataframe(pickle), json; txt도 가능)
오늘은 Pandas의 기술통계와 결측값(NA)처리에 대해 알아보자.
3. 기술통계
데이터프레임에 대한 간단한 기술통계 자료를 한 눈에 보여주는 코드 .describe()
먼저 데이터프레임을 만들어보자.
#데이터프레임에 대한 간단한 요약 통계
#numpy의 random 함수로 난수를 생성해보자.
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(5, 5), columns = list('ABCDE'))
df

이제 .describe()로 요약통계값을 살펴보자.
#데이터프레임 요약통계
df.describe()
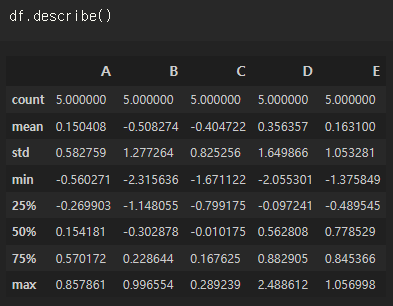
.describe() 함수로 전체 카운트수와 평균, 표준편차, 최댓값과 최솟값, 사분위수를 알 수 있다. (총 8가지 항목)
4. 결측값 처리
결측값 처리는 전처리에 있어 중요한 과정이다.
먼저 결측치를 갖는 데이터를 생성해보았다.
#결측치 처리를 위해 결측값이 포함된 데이터프레임을 생성
ex = pd.DataFrame(np.random.randn(6,6), columns = list('ABDCEF'))
ex.loc[2:4, 'A'] = None
ex.loc[3, ['C','E']] = None
ex

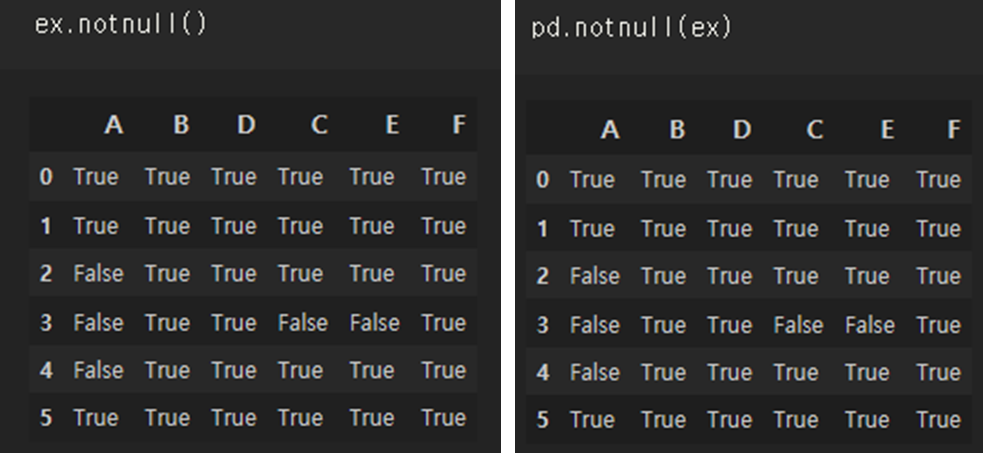
4-1. 결측치 확인 .isnull() 과 .notnull()
.isnull 함수는 전체 데이터프레임에 대해서, NA라면 True를, NA가 아니라면 False를 출력한다.
#결측치 확인 using .isnull()
ex.isnull() #isnull(ex)도 같은 함수로 같은 결과를 보여줌

반대로 결측치가 아니면 True를 반환하는 .notnull() 함수도 있다.
#결측값의 위치 확인 with .isnull() or .notnull()
#.notnull() 결측치가 NULL값이 아니면 True, Null이면 False
ex.notnull() #pd.notnull(ex)도 같은 함수로 같은 결과를 보여줌
특정 칼럼에 대해서만 결측치 위치 확인하기 --- 데이터명[['칼럼1','칼럼2']].isnull()
만약 특정 칼럼에 대해서만 결측치의 위치를 확인하고 싶다면 ## 데이터명[['칼럼1','칼럼2']].isnull() ## 을 사용한다.
#특정 칼럼에 대해서만 결측치의 위치 확인
ex[['A','B']].isnull()

.isnull() 혹은 .notnull()함수는 각 결측치의 위치를 확인할 수 있지만, 데이터가 커질 때는 이를 전부 확인하기 힘들기때문에 보통 총 결측치가 몇 개인지 column별로 확인을 하거나, 전체 결측치의 수를 확인하는 경우가 많다.
이 경우에는 .isnull().sum() 을 사용한다.
칼럼별 결측치 개수 확인 함수 .isnull().sum()
#칼럼별 결측치의 개수 구하기
ex.isnull().sum()
#칼럼별 결측치가 아닌 값의 개수 구하기
ex.notnull().sum()

행별 결측치 개수 확인 .isnull().sum(1)
행별로도 결측치의 개수를 확인할 수 있다.
### .isnull().sum(1) ### 칼럼별 계산하는 것과 같은데 sum의 괄호 안에 1을 넣으면 된다.
#행별 결측치의 개수 구하기
ex.isnull().sum(1)
#행별 결측치가 아닌 것의 개수 구하기
ex.notnull().sum(1)

행별 결측치의 개수를 새로운 칼럼으로 만들어줄 수도 있다. (쉬움)
#행별 결측치의 개수를 새로운 칼럼으로 추가하기
ex['sum_NA'] = ex.isnull().sum(1)

4-2. 결측치 대체하기 (.fillna() 함수)
전처리 과정에서 결측치를 대체하는 방법은 보통 네가지가 있다.
- 결측값을 특정 값으로 대체
- 결측치 바로 앞(혹은 뒤)과 같은 값으로 대체
- 결측치를 칼럼 평균으로 대체
- 결측값을 다른 변수 값으로 대체
결측치를 처리할 방법은 분석방법에 맞는 것을 적절하게 판단하여 결정해야 한다.
결측값을 특정 값으로 대체하기
### 데이터명.fillna(값) ### 으로 결측값을 특정값으로 대체할 수 있다.
#결측치 대체하기
#결측치를 특정 값으로 대체하기
ex.fillna(0)

결측치를 바로 앞과 같은 값으로 대체하기 .fillna(method = 'ffill') 혹은 method = 'pad'
###데이터명.fillna(method = ffill) ### 즉 옵션 중에 method = 'ffill' 혹은 'pad'를 이용한다.
#결측치를 바로 앞과 같은 값으로 대체하기
ex.fillna(method = 'ffill')
#method = 'pad'도 같은 결과
ex.fillna(method = 'pad')

혹시 연속되지 않은 결측치에는 어떻게 처리될까 궁금해서 새로운 결측치를 추가하여 한 번 더 수행해본 결과

결측치를 바로 뒤와 같은 값으로 대체하기 .fillna(method = 'bfill') 혹은 method = 'backfill'
뒤와 같은 값으로 대체하는 것도 옵션에서 method만 바꿔주면된다.
#결측치를 바로 뒤와 같은 값으로 대체하기
ex.fillna(method = 'bfill')
#method = 'backfill'도 같은 결과
ex.fillna(method = 'backfill')

결측치를 칼럼 평균으로 대체 .fillna(.mean())
보통 결측치를 해당 칼럼의 평균값으로 대체하는 방법을 많이 사용한다.
이 경우는 각 칼럼의 평균을 직접 계산하여 .fillna()의 괄호 안에 넣어줘도 되고,
###데이터명.fillna(데이터명.mean())### 함수를 사용해도 된다.
#결측치를 해당 칼럼의 평균치로 대체하기
ex.fillna(ex.mean())

결측치를 다른 변수의 값으로 대체하기
[Python pandas] 결측값 채우기, 결측값 대체하기, 결측값 처리 (filling missing value, imputation of missing valu
지난번 포스팅에서는 결측값 여부 확인, 결측값 개수 세기 등을 해보았습니다. 이번 포스팅에서는 결측값을 채우고 대체하는 다양한 방법들로서, - 결측값을 특정 값으로 채우기 (replace missi
rfriend.tistory.com
(위 블로그에서 다른 변수로 대체하는 법을 참고했다.)
이렇게 만들 때는 numpy패키지의 np.where() 함수를 사용한다.
#결측치를 다른 칼럼의 값으로 대체하기
#np.where(조건1, 행동1, 행동2)로 조건1이 맞으면 행동1을, 조건1이 틀리면 행동2를 하라는 함수
#np.where() 함수를 활용해 A열의 결측치를 B열 같은 행의 값으로 대체해보자.
ex['A'] = np.where(pd.notnull(ex['A']) == True, ex['A'], ex['B'])
ex

위의 네가지 방법을 보면 알겠지만, 보통 .fillna() 함수에 옵션을 붙이거나, 특정 값을 집어넣는 방식으로 대체하고,
다른 변수의 값으로 대체하는 것만 np.where() 함수를 활용했다.
결측치 제거하기 (.dropna(axis = ))
데이터는 굉장히 큰데 결측치의 개수가 적다면 아예 결측치가 있는 행을 제거해버리는 것도 자주 활용되는 방법이다.
이때는 .dropna() 를 활용한다.
결측치가 있는 행 제거하기 (.dropna(axis = 0))
결측치가 있을 때 보통 칼럼을 제거하기 보다 해당 행만 제거하는 경우가 많다.
#결측치 제거하기
#결측치가 있는 행만 제거하기
ex.dropna(axis = 0)

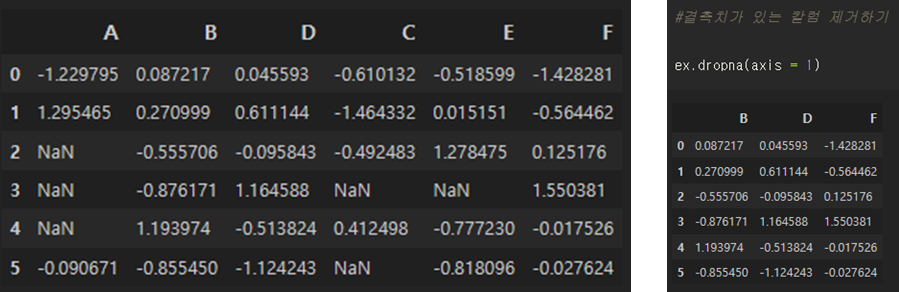
결측치가 있는 열 제거하기 (.dropna(axis = 1))
반대로 결측치가 있는 행은 axis = 옵션에 1을 넣으면 된다.
#결측치가 있는 칼럼 제거하기
ex.dropna(axis = 1)
4-3. 결측치 보간하기 (interpolation)
보간(interpolation)은 잃어버린 데이터를 추측으로 다시 채워넣는 것이다.
결측치 보간은 주로 Series형에서 활용된다.
보간 방법은 아래의 블로그글을 참고했다.
teddylee777.github.io/pandas/pandas-interpolation
Pandas를 활용한 결측치 보간(interpolation) 하기
Pandas를 활용한 결측치 보간(interpolation) 하는 방법에 대해 알아보겠습니다.
teddylee777.github.io
일단 모든 패키지를 import
#결측치 보간하기(interpolation)
#numpy, pandas 패키지랑 matplotlib, scipy, math, warnings 패키지 모두 import 할 것
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
import math
import warnings
#블로그에서 추가한 설정(뭔지는 모르겠음)
warnings.filterwarnings('ignore')
%matplotlib inline
코딩 역시 위의 블로그를 그대로 따라했다.
#평균 = 0, 분산 = 1 인 정규분포 생성
mu = 0
var = 1
#sigma (표준편차 계산)
sigma = math.sqrt(var)
x = np.linspace(mu - 3*sigma, mu + 3*sigma) #평균 0을 기준으로 +-3시그마 만큼을 x의 범위로 설정
#랜덤한 10개의 데이터를 삭제하고 10개 구간 만듦
idx = np.random.choice(len(x), size = 10)
x[idx] = np.nan #nan으로 데이터 none화
#정규분포 시각화
plt.plot(x, stats.norm.pdf(x, mu, sigma))
plt.show()

#결측 개수 확인
#먼저 x를 Series화하면서 결측치 개수 계산
pd.Series(x).isnull().sum()

#Series화된 x에서 NaN 위치 확인
pd.Series(x).head(20)

보간을 활용한 결측치 대입 (.interpolate())
#보간을 통해 채워넣기
x_inter = pd.Series(x).interpolate()
x_inter.head(20)

#보간 이후 채워진 값 시각화
plt.plot(x_inter, stats.norm.pdf(x_inter, mu, sigma))
plt.show()

보간의 상세한 옵션은 위 블로그에 나와있는데 한 번 보자면
<옵션>
1. method = '~'
- linear (default) : index를 무시하고 값을 동일한 간격으로 처리
- time : 주어진 간격의 길이를 보간하기 위해 매일 더 높은 해상도 데이터를 처리
- values : 인덱스의 실제 숫자 값을 사용
- pad : 기존 값을 사용해 NaN 채움
2. axis = 0 or 1 : 보간할 축 설정
3. limit = 숫자 : 채울 최대 연속 NaN의 개수
4. inplace = True (default는 False) : 변경된 데이터 적용하려면 True로 설정
5. limit_direction = '~'
- forward : 위에서 아래 순서로 연속 NaN이 채워짐
- backward : 아래에서 위 순서로 연속 NaN이 채워짐
- both : 양 방향에서 가운데로 채워짐
-- 즉 연속된 NaN이 있으면 그 방향으로 내려오면서 하나만 채워주고 그 다음 결측치는 비워두는 것
아래 두 개는 별로 안 봐도 될 것 같아서 패스
6. limit_area = 'None, inside, outside'
7. downcastoptional = 'infer' or 'None'
결측치 처리에 대해 지나칠 정도로 많이 알아본 것 같다.
이정도만 처리할 줄 알아도 충분히 훌륭한 전처리를 해낼 수 있다고 생각한다.
Pandas를 숙달되게 사용할 수 있을 때까지 열심히 연습하자..!



