(Pandas 라이브러리로 할 수 있는 일들을 조사해보고 정리하는 글입니다.)
Python은 R처럼 데이터/통계 분석용으로 만들어진 프로그램이 아니라 프로그래밍용 언어이기 떄문에 일반적으로 통계분석을 위한 라이브러리를 따로 설치하여 사용한다.
라이브러리란 개념은 파이썬에 내장되어있는 기본 함수들을 제외하고 다른 기능들을 포함해 만들어놓은 패키지라고 생각하면 될 것 같다.
라이브러리 중에서도 통계분석에 빼놓을 수 없는 패키지가 바로 Pandas다.
Pandas
<기능 요약 정리>
- Data frame 자료형 만들기
- Series 자료형 만들기
- 기술통계
- NA값 처리
- 엑셀 파일 불러오기 (파일 형식: xlsx, csv, Pandas_dataframe(pickle), json; txt도 가능)
위의 기능들이 Pandas의 대표적인 기능이라고 한다.
오늘은 Pandas의 기능 중 Data frame 관련된 함수들을 보려고 한다.
Pandas의 기능을 살펴보기 전에 먼저 라이브러리 설치에 대해 알아보자.
- Pandas 라이브러리 설치 (Anaconda 기준)
Anaconda Prompt에 conda install pandas 입력


- 패키지(라이브러리)를 불러올 때는?
'import 패키지 as 줄임말' 로 패키지를 불러올 수 있다.
import pandas as pd(일반적으로 pandas는 pd로 축약한다.)
1. Data frame 자료형 만들기
Pandas 라이브러리를 통계분석에 많이 사용하는 이유 첫번째는 데이터프레임화가 가능하기 때문이다.
특히 테이블 형식의 데이터를 다룰 때 data frame을 자주 사용하게 된다.
이 기능을 통해 1) 데이터프레임 구조 파악 2) 특정 데이터 행, 열 출력 3) 새로운 데이터 추가, 삭제 4) 데이터프레임 수정 등을 할 수 있다.
1-1. 데이터프레임 생성
Python - Pandas 튜토리얼 (데이터프레임 생성, 접근, 삭제, 수정)
Pandas (Python Data Analysis Library) 파이썬을 통해 데이터 분석을 할 때, Pandas를 빼놓고 이야기할 수 없다. 온전히 통계 분석을 위해 고안된 R 과는 다르게 python은 일반적인 프로그래밍 언어(general purp..
3months.tistory.com
(위 블로그를 참고했다.)
- Pandas의 data frame은 ndarray, list, dict, series, dataframe 등의 데이터 형식을 모두 데이터프레임화 할 수 있다.
1) 기본적인 data frame 생성 방법
#data frame 생성
df = pd.DataFrame((1,2,3,4),(1,2,3,4),columns = ['a'])
df

2) array 행렬 데이터 프레임화
(array를 써서 행렬을 만들기 위해서 먼저 numpy를 import 해야한다.)
먼저 array로 행렬을 만들면
import numpy as np
ar = np.array([[1, 2, 3], [4, 5, 6]])
ar

array 형식을 dataframe화 해주면
#array를 데이터프레임화
import numpy as np
ar = np.array([[1, 2, 3], [4, 5, 6]])
ar = pd.DataFrame(ar)
ar

3) dictonary형식 데이터프레임화
#dictionary 데이터프레임화
dic = {"a": ['1', '2'], "b": ['3', '4']}
dic

#dictionary 데이터프레임화
dic = {"a": ['1', '2'], "b": ['3', '4']}
dic = pd.DataFrame(dic)
dic
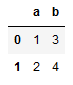
모두 성공적으로 데이터프레임이 된다.
1-2. 데이터프레임에서 자료 살펴보기
1) 차원 보기 (.shape)
위에서 생성한 데이터프레임의 차원을 shape로 확인할 수 있다.
데이터명.shape(df.shape, ar.shape, dic.shape)


2) 데이터프레임에서 특정 행(로우), 열(칼럼) 보기
먼저 dictionary 형식으로 데이터프레임을 만들어보자.
dt = {'name':['kim','lee','son','you'], 'age':['21','30','19','28'],
'position':['MF','FW','GK','DF'],'goal':['1','4','0','0']}
dt = pd.DataFrame(dt,index = [1,2,3,4])
dt

이제 데이터프레임의 칼럼(열)을 조회해보자.
존재하는 모든 칼럼명 조회하기 (.columns)
.columns를 써서 데이터 프레임에 존재하는 모든 칼럼명을 조회할 수 있다.
#데이터프레임의 모든 칼럼명 조회
dt.columns

기본적인 칼럼 조회는 데이터명['칼럼']
#칼럼 전체 조회
데이터명['칼럼']
dt['name']

이 경우 데이터가 series 형식(1차원 배열구조)으로 조회된다.
동시에 여러 칼럼을 조회하려면 대괄호를 두 번 적고 그 안에
칼럼명을 입력한다.
(여기서 깨달은 점: 여러 행 혹은 열을 표현하기 위해 list형식을 사용한다.)
#두 개 이상의 열을 조회하려면 대괄호가 두 개
데이터명[['칼럼1','칼럼2']]
dt[['name','age']]

로우(행) 조회 (.loc['인덱스명'])
행을 조회하는 것은 .loc['index명'] 혹은 .iloc['index번호'] 을 사용한다.
위에서 만든 동일한 데이터에서 행을 조회해보자.
dt = {'name':['kim','lee','son','you'], 'age':['21','30','19','28'],
'position':['MF','FW','GK','DF'],'goal':['1','4','0','0']}
dt = pd.DataFrame(dt,index = [1,2,3,4])
#특정 행 조회(인덱스로 조회)
#데이터명.loc['index명']
dt.loc[1]

동시에 여러 행 조회
범위를 지정해주는 :를 사용해 지정하고자 하는 인덱스 사이에 입력해준다.
#여러 행 조회 (인덱스 범위 설정)
#데이터명.loc['인덱스1':'인덱스n']
dt.loc[2:4]
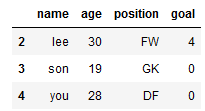
동시에 여러 행을 조회하면서 몇 가지 칼럼만 조회하기 (.loc['인덱스1':'인덱스n',['칼럼명1','칼럼명2']])
다시 말하면 특정 칼럼을 조회할 때 몇 개 행만 조회하는 방법이다.
#여러 칼럼을 조회하면서 특정 행만 조회하기
dt.loc[2:3,['age','goal']]
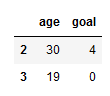
.loc 함수로 행과 열을 모두 범위인덱싱 할 수도 있다. (생략)
.loc함수만 있으면 어떤 범위든 상관없이, 내가 원하는 행과 열을 조회할 수 있다.
.iloc함수는?
.iloc 함수는 인덱스명이 아니라 인덱스 숫자로 행과 열을 조회할 수 있는 함수이다.
※주의할 점은 인덱스 숫자는 저번에 공부했듯이 0부터 시작한다는 점
그리고 a:b처럼 범위인덱싱할 때는 뒤의 인덱스 숫자(b)의 바로 앞까지만 조회를 해준다는 점
#iloc함수 활용
#인덱스 숫자로 조회하는 함수이므로 인덱스 순서(0부터 시작)대로 출력된다.
dt.iloc[[1,3],2:4]

인덱스로 로우는 인덱스가 1, 3에 해당하는 2와 4번째 행을 출력했고,
칼럼은 인덱스 2부터 4의 앞인 인덱스 3에 해당하는 칼럼 즉 3, 4번째 칼럼인 position과 goal 칼럼이 출력되었다.
특정 조건에 해당하는 행의 특정 칼럼만 조회하기 (.loc 인덱싱 활용)
상당히 활용도가 높은 조회방식이다.
ex1) 이름이 son인 사람 조회
#이름이 'son'인 사람의 모든 칼럼 조회
dt.loc[dt['name'] == 'son', : ]

ex2) 이름이 son인 사람의 나이와 포지션 칼럼 조회
#이름이 son인 사람의 나이와 포지션 조회
dt.loc[dt['name'] == 'son', ['age','position'] ]

ex3) 1골 넘게 골을 넣은 사람의 나이 칼럼 조회
#1골 넘게 넣은 사람의 나이 칼럼 조회
#먼저 goal칼럼이 object로 저장되어 있어서 astype으로 int로 변환
dt['goal'] = dt['goal'].astype(int)
dt.loc[dt['goal']>1,'age']
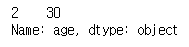
ex4) 이름이 'lee'이면서 (and, &) goal을 한 골 넘게 넣은 사람의 age칼럼을 조회
(여기서 다른 논리연산자인 or을 시도해봤는데 안된다.)
#특정 조건에 해당하는 행의 특정 칼럼 조회하기
#이름이 'lee' 이면서 goal을 한 골 넘게 넣은 사람들의 age 칼럼만 출력하기
#먼저 goal칼럼이 object로 저장되어 있어서 astype으로 int로 변환
dt['goal'] = dt['goal'].astype(int)
dt.loc[(dt['name'] == 'lee') & (dt['goal']>= 1), 'age']

위에서 배운 특정 조건에 해당하는 행을 조회하는 방법을 활용해서,
특정 조건 행의 칼럼에 새로운 값 추가도 가능하다.
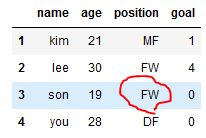
'son'의 포지션을 공격수로 바꿔보자.
#특정 조건행의 칼럼에 새로운 값 넣기
dt.loc[dt['name'] == 'son', 'position'] = 'FW'
3) 새로운 칼럼 추가 (새로운 칼럼 만들고 값 추가하기)
새로운 칼럼 추가
새로운 칼럼을 추가하고 싶을 땐,
## 데이터명['새칼럼명'] = ['행1', ... ,'행n'] ##
이렇게 새로운 리스트를 만들어서 집어넣으면 된다.
(만약 모든 행에 같은 값을 넣을 거라면 ## 데이터명['새칼럼명'] = '내용' ##을 입력해서 모든 행에 같은 '내용'이 입력된다.)
dt = {'name':['kim','lee','son','you'], 'age':['21','30','19','28'],
'position':['MF','FW','GK','DF'],'goal':['1','4','0','0']}
dt = pd.DataFrame(dt,index = [1,2,3,4])
#위의 데이터프레임에 새로운 칼럼 추가하기
#새로운 칼럼의 모든 행에 일괄적인 내용 추가하기
dt['nationality'] = 'korea'
#새로운 칼럼의 각 행마다 다른 내용 추가하기
dt['salary'] = [10, 30, 50, 40]

새로운 칼럼 추가(np.arange, series형식 추가)
뿐만 아니라 numpy 패키지의 arange를 이용해서 새로운 칼럼의 값을 대입시킬 수도 있고,
위에서 각 칼럼을 조회할 때 series 형식으로 조회된다고 했는데, 반대로 series 형식의 데이터를 칼럼에 추가할 수도 있다.
Series 자료형에 대한 자세한 설명은 아래에서 할 것이니 참고.
#새로운 칼럼 추가하기
#numpy패키지의 arange 사용해서 새로운 칼럼 생성하고 값 대입하기
dt['back_num'] = np.arange(4)
#Series 형식 데이터 생성 후에 새로운 칼럼으로 추가하기
nationality = pd.Series('korea', index = (1,3))
dt['국적'] = nationality

4) 칼럼(열) 삭제 (del, drop)
이번에는 열을 삭제하는 법을 알아보자.
pandas에서 열을 삭제하는 방법에는 3가지가 있다.
del로 칼럼 삭제
## del 데이터['열'] ## 로 삭제가 가능하다.

#특정 칼럼 삭제하기
#del 데이터명['칼럼']
del dt['salary']

.drop으로 칼럼 삭제하기
.drop(['칼럼1', '칼럼2'], axis = 'columns', inplace = True) 로 여러 칼럼을 동시에 삭제할 수 있다.
혹은 axis = 1로 입력해도 됨
#특정 칼럼 삭제하기
#.drop(['칼럼1','칼럼2'],axis = 'columns', inplace = True)
#혹은 #.drop(['칼럼1','칼럼2'],axis = 1, inplace = True)
#age와 nationality 칼럼을 삭제해보자
dt.drop(['age','nationality'], axis = 'columns', inplace = True)

※주의, inplace 옵션(inplace = False가 default)은 변경을 적용해주는 옵션이다. 만일 여기서 inplace = True로 옵션을 설정해주지 않으면 변경된 내용이 기존 데이터프레임에 적용되지 않는다.
#inplace = False인 경우
dt.drop('name', axis = 'columns', inplace = False)
dt

이 경우는 앞에 dt = 을 붙여서 영구적으로 데이터프레임이 바뀔 수 있도록 해주면 된다.
dt = dt.drop('name', axis = 'columns', inplace = False)

행 삭제하기 (.drop에 인덱스명을 넣어서)
행을 삭제하는 것 또한 .drop 함수를 이용하면 된다.
이때는 인덱스명을 적용해서 하면 된다.
위의 예제에서 1, 2번째 행을 drop 해보자.
#특정 행 삭제하기
#1, 2번째 행을 삭제 해보자
#.drop([index1, index2], axis = 0, inplace = True)
#여기서 인덱스는 맨 왼쪽 인덱스 칼럼에 적힌 인덱스명
dt.drop([1, 2], axis = 0, inplace = True)

여기까지 Pandas 패키지에서 Data frame을 생성하고, 데이터프레임에서 특정 행과 열을 조회하고, 새로운 칼럼을 추가하고, 특정 행과 열을 삭제하는 법을 살펴보았다.
오늘 배운 함수들은 전부 기가 막히게 쓸 일이 많은 함수들이다.
까먹었을 때 검색하면 다시 금방 찾을 수 있는 함수들이지만 실제 분석과정에서 이 정도 함수를 완벽하게 적용할 수 있는 상태인 사람이랑 검색해서 찾는 사람의 갭은 엄청 클 것이다.
그러니 부디 열심히 공부하고 적용해서 이정도는 진짜 까먹지 말고 자유자재로 쓰도록 연습하자. (나한테 하는 말..)
'언어 > Python' 카테고리의 다른 글
| [개념] Python Pandas에 대해 이해해보자 3 (기술통계, 결측값 처리, 각종 파일 형식 불러오기와 내보내기) (0) | 2020.08.27 |
|---|---|
| [개념] Python Pandas에 대해 이해해보자 2 (Series 자료형 생성, Series형 조회, Series형 사칙연산) (0) | 2020.08.25 |
| [기본] Python 조건문(비교 연산자, 논리 연산자, 기본조건문) (0) | 2020.08.22 |
| [기초] Python 강제 형 변환(str, int, float) (0) | 2020.08.22 |
| [기초] Python 입력, 출력 함수 (input, print) (0) | 2020.08.22 |



