2020/11/07 - [연습장] - [Kaggle] 파이썬에서 함수 정의해서 파이차트 만들기 (Titanic 예제 활용)
저번 포스팅에 이어서 오늘은 막대그래프를 그려보기로 한다.
cyc1am3n.github.io/2018/10/09/my-first-kaggle-competition_titanic.html
캐글 타이타닉 생존자 예측 도전기 (1)
이번에는 캐글의 입문자를 위한 튜토리얼 문제라고 할 수 있는 Titanic: Machine Learning from Disaster 의 예측 모델을 python으로 풀어보는 과정에 대해서 포스트를 할 것이다.
cyc1am3n.github.io
(※이번 포스팅은 위의 깃허브 코드를 사용했습니다.)
오늘 공부할 코드
#SibSp, Parch 변수를 보기 위해 bar plot 만들기
#코드 출처: https://cyc1am3n.github.io/2018/10/09/my-first-kaggle-competition_titanic.html
def bar_chart(feature):
survived = train[train['Survived'] == 1][feature].value_counts()
dead = train[train['Survived'] == 0][feature].value_counts()
df = pd.DataFrame([survived, dead])
df.index = ['Survived', 'Dead']
df.plot(kind = 'bar', stacked = True, figsize = (10, 5))저번에 공부한 pie_chart() 함수와 거의 동일해서 포스팅을 날로먹을 예정이다.
1. def 함수로 bar_chart() 함수 정의
저번에 def 함수에 대해 공부한 것과 동일하다.
우리는 bar_chart()라는 함수를 만들려고 한다.
2. 변수 정의
2-1. survived, dead 변수로 생존자와 사망자 빈도수 구분
survived = train[train['Survived'] == 1][feature].value_counts()
dead = train[train['Survived'] == 0][feature].value_counts()2-2. survived와 dead 변수 데이터프레임화
df = pd.DataFrame([survived, dead])막대그래프는 데이터프레임을 이용해 만들 수 있다.
우리는 생존자와 사망자 그룹 내에서 형제, 자매, 배우자의 총 인원(SibSp)과 부모, 자식의 총 인원(Parch)수의 비중을 알아보고자 한다.
우리가 지정한 survived, dead 변수는 칼럼이 하나인 Series형이다.
Series형을 데이터프레임화하는 것은 pd.DataFrame() 함수로 간단히 가능하다.
또한, survived와 dead 변수는 모두 한 feature에서 만든 것이므로 두 변수의 범주가 다르지 않아 데이터프레임화가 가능하다.
2-3. 데이터프레임에서 인덱스 정하기
df.index = ['Survived', 'Dead']방금 합친 데이터프레임의 인덱스는 모두 feature명으로 출력된다.
이를 수정해주기 위해 인덱스명을 직접 지정해준다.

3. 막대그래프로 만들어주기
#막대그래프 생성
df.plot(kind = 'bar', stacked = True, figsize =(10,5))데이터프레임을 플롯으로 만들어주는데 종류는 'bar'로 막대그래프를 만든다.
stacked = True 옵션으로 누적 막대그래프를 만든다.
stacked 옵션을 사용하지 않으면 일반적인 그래프를 출력한다.

figsize = (10,5)) 로 지정하여 default 값보다 더 크게 출력해 보기 좋게 만든다.
4. 결과 출력 및 해석
print([bar_plot('SibSp'), bar_plot('Parch')])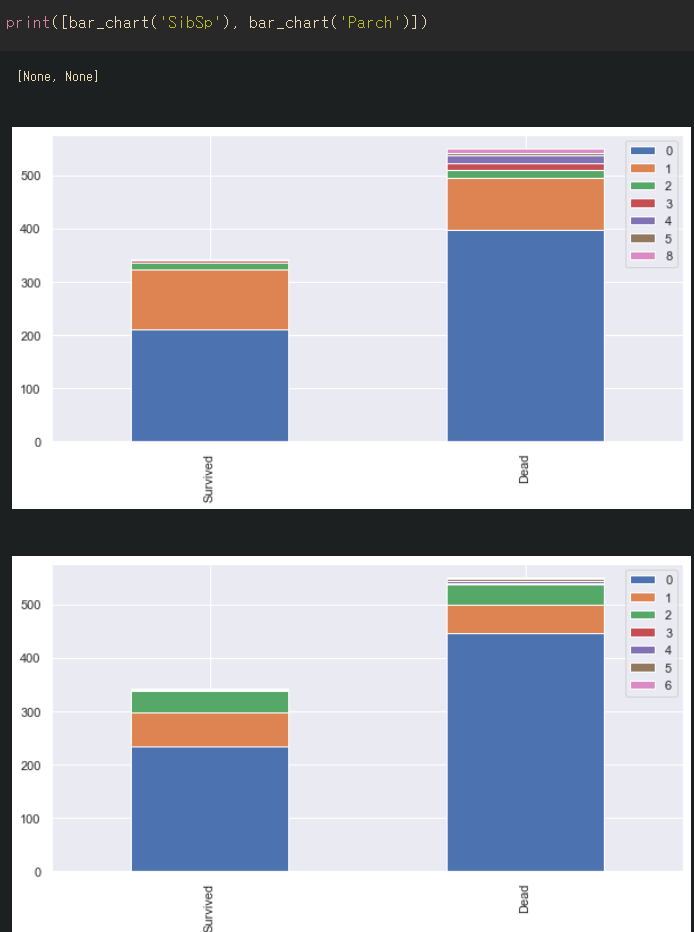
비율이 눈에 잘 안 들어와서 파이차트로 전환해서 대강 확인했다.
형제, 자매나 배우자의 총 인원 합이 2, 3명일 때 생존 비율이 가장 높았다.
부모, 자식 등 총 인원의 합이 0명일 때 사망자 비율이 높았고, 1명 이상일 때는 50%이하의 사망률이 나타났다.
이번에는 barplot을 그리기 위해서 데이터프레임으로 만들어야 한다는 사실과 df.plot() 함수에서 kind = 옵션을 'bar'로 지정해주는 것, stacked 옵션과 figsize 옵션을 배웠다.
데이터에 대한 인사이트를 종합하자면,
여성의 생존 비율이 남성보다 압도적으로 높은데 이는 여성과 아이부터 구출했던 까닭으로 보이고,
1등석의 생존률이 높은 것은 티켓 등급에 따른 객실 배치 여부가 달라서 생기는 것인 듯하다.
승선장에서 생존률의 차이가 생긴 것은 Cherbourg 승선장에서 탑승한 인원들의 객실 배치가 가장 생존에 유리한 위치로 배정됐던 것이 아닐까 추측해볼 수 있겠다.
형제, 자매, 배우자 인원 수나 부모, 자식 인원 수와 생존여부의 인과관계는 파악하기 어렵지만, 홀로 탑승한 승객이 생존에 불리하다는 점은 확실한 것으로 보인다.
아무래도 홀로 탑승한 경우 도움을 받을 사람이 더 적으므로 이러한 차이가 발생한 것 같다.
이런 경향을 참고해서 생존 여부를 예측할 수 있겠다.
예측을 위해 다음에는 전처리 과정을 공부해보자.
'연습장' 카테고리의 다른 글
| [Kaggle] 캐글 상위권 코드 보고 공부하는 타이타닉 예제 심화 EDA 1 (성별, 등급, 나이 특성 확인) (0) | 2020.11.11 |
|---|---|
| [Kaggle] 타이타닉 예제 전처리 (0) | 2020.11.09 |
| [Kaggle] 파이썬에서 함수 정의해서 파이차트 만들기 (Titanic 예제 활용) (0) | 2020.11.07 |
| [예제] Python 조건문 심화 예제 4 (세 정수 중 가장 큰 정수 출력) (0) | 2020.08.24 |
| [예제] Python 조건문 심화 예제 3 (백화점 이벤트 예제) (0) | 2020.08.24 |



