2장 SQL 활용
4절 그룹 함수
그룹 함수는 GROUP BY문에 대한 SUBTOTAL을 계산해준다.
1. ROLLUP
GROUP BY ROLLUP(칼럼1, 칼럼2) : (칼럼1별 합계), (칼럼1별 칼럼2별 합계), (전체 합계)를 계산
※ ROLLUP (칼럼1, 칼럼2) = ROLLUP (칼럼1, (칼럼1, 칼럼2))
2. GROUPING SETS
GROUP BY GROUPING SETS(칼럼1, 칼럼2): (칼럼1별 합계), (칼럼2별 합계)를 계산
3. CUBE
GROUP BY CUBE(칼럼1, 칼럼2): (전체 합계), (칼럼1별 합계), (칼럼2별 합계), (칼럼1별 칼럼2별 합계) 계산
ROLLUP, GROUPING SETS, CUBE 함수는 한 번에 비교해서 외우는 것이 좋다.
##GROUP FUNCTION - ORACLE 방식 #ROLLUP SELECT DEPTNO, JOB, SUM(SAL) FROM EMP GROUP BY ROLLUP (DEPTNO, JOB); #GROUPING SETS - ORACLE만 됨 SELECT DEPTNO, JOB, SUM(SAL) FROM EMP GROUP BY GROUPING SETS (DEPTNO, JOB); #ROLLUP - ORACLE만 됨 SELECT DEPTNO, JOB, SUM(SAL) FROM EMP GROUP BY CUBE (DEPTNO, JOB);
#GROUP FUNCTION - MySQL식 #ROLLUP SELECT DEPTNO, JOB, SUM(SAL) FROM EMP GROUP BY DEPTNO, JOB WITH ROLLUP;
(1) ROLLUP 결과
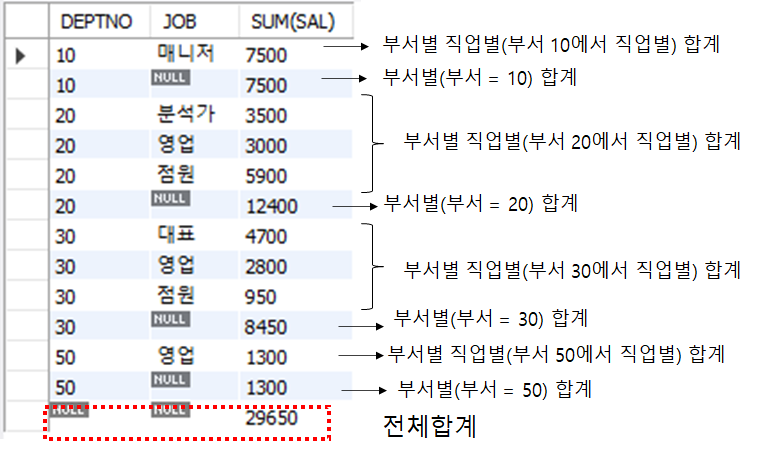
이런 식으로 해서 GROUPING SETS는 부서별 합과 직업별 합만 깔끔하게 출력
grouping sets(col1, col2)를 썼다면 col2별 합계가 먼저 나오고 그 다음 col1별 합계가 나온다.
만약 Grouping sets를 사용해 칼럼1별 합계와 칼럼1별 칼럼2별 합계를 구현하고 싶다면?
: grouping sets (col1, (col1, col2))
grouping sets 함수로 전체합계를 구현하고 싶다면
: grouping sets (col1, ( ) )
CUBE 함수는 전체 합계와 부서별 합과, 직업별 합, 부서별 직업별 합을 출력
이 세 가지 그룹함수를 구분하는 것이 굉장히 중요하다.
5절 윈도우 함수
1. 윈도우 함수
: 행과 행 간의 관계를 정의하기 위해 제공되는 함수
<윈도우 함수 구조>
SELECT 윈도우함수(ARGUMENTS)
OVER (PARTITION BY 칼럼
ORDER BY WINDOWING절)
FROM 테이블;
- ARGUMENTS(인수) : 윈도우 함수에 따라서 0~N개의 인수를 설정
- PARTITION BY : 전체 집합을 기준에 의해 소그룹으로 나눔
- ORDER BY : 어떤 항목에 대한 정렬
- WINDOWING : 행 기준의 범위를 정함 -ROWS는 물리적 결과의 행 수 / - RANGE는 논리적인 값에 의한 범위
<WINDOWING>
| 구조 | 설명 |
| ROWS | 부분집합인 윈도우 크기를 물리적 단위로 행의 집합을 지정 |
| RANGE | 논리적인 주소에 의해 행 집합 지정 |
| BETWEEN ~ AND | 윈도우의 시작과 끝의 위치를 지정 |
| UNBOUNDED PRECEDING | 윈도우의 시작 위치가 첫번째 행 |
| UNBOUNDED FOLLOWING | 윈도우의 마지막 위치가 마지막 행 |
| CURRENT ROW | 윈도우 시작 위치가 현재 행 |
<WINDOWING 사용 예시>
##윈도우 함수 #WINDOWING 사용 SELECT EMPNO, ENAME, SAL, SUM(SAL) #사번, 이름, 급여, 급여합을 조회해줘 OVER (ORDER BY SAL #근데 SUM(SAL)칼럼의 합계를 구할 때 말이야 ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) #급여순으로 나열했을때, 합계를 지금 행부터 맨 마지막 행까지 합계로 계산해줘 TOTSAL FROM EMP; #그리고 그 SUM(SAL)칼럼 이름은 TOTSAL로 하자
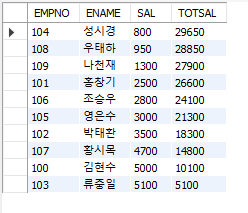
윈도우 함수는 이런 계산을 가능하게 하는 함수다.
PARTITON BY문까지 활용해보자.
<PARTITOIN BY문 활용>
#WINDOWING에 PARTITION BY문까지 사용 #위에서 계산한거랑 같은데 PARTITION BY문을 써서 부서별로 계산하도록 함 SELECT DEPTNO, EMPNO, ENAME, SAL, SUM(SAL) OVER (PARTITION BY DEPTNO #부서별로 계산해줘! ORDER BY SAL ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) TOTSAL FROM EMP;
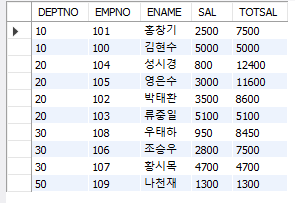
복잡해보이지만 PARTITION BY문으로 부서별로 계산을 하도록 만든 것이다.
2. 순위 함수
<순위 관련 윈도우 함수>
| 순위 함수 | 설명 |
| RANK( ) | ex) 공동 2위가 있다면 1, 2, 2, 4등으로 순위를 매김 |
| DENSE_RANK( ) | ex) 공동 2위가 있으면 1, 2, 2, 3등으로 순위를 매김 |
| ROW_NUMBER( ) | ex) 공동 2위에게 다른 순위 매김, 1, 2, 3, 4로 만듦 |
#순위 함수 #rank select ename, sal, #직원명이랑 급여 rank() over (order by sal desc) all_rank, #all_rank라는 칼럼명으로 순위를 계산하는데 급여(내림차순)으로 순위 매겨주고 rank() over (partition by job order by sal desc) job_rank #job_rank라는 칼럼명으로 순위를 계산하는데 여기서는 직업별로 묶어서 급여(내림차순으로) 순위 매겨줘 from emp;
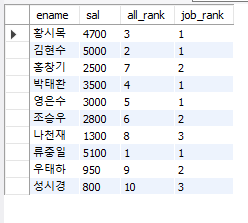
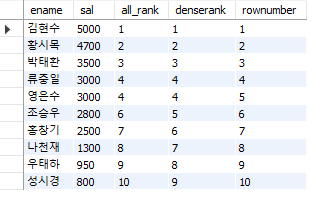
전체 순위를 계산하고 직업별로 묶었을 때 직업 내에서의 급여 순위도 계산하도록 만들었다.
동수 비교를 위해 먼저 데이터를 살짝 수정해준다.
#동수 비교를 위한 데이터 수정 update emp set sal = 3000 where empno = 103; #rank, dense_rank, row_number 비교 select ename, sal, rank() over (order by sal desc) all_rank, dense_rank() over (order by sal desc) denserank, row_number() over (order by sal desc) rownumber from emp;
3. 집계 함수
| 집계 함수 | 설명 |
| SUM | 합계 |
| AVG | 평균 |
| COUNT | 행 수 계산 |
| MAX, MIN | 최댓값, 최솟값 |
그동안 많이 썼으니 따로 언급은 하지 않겠다.
4. 행 순서 관련 함수
| 행 순서 관련 함수 | 설명 |
| FIRST_VALUE(칼럼) | - 파티션에서 가장 처음에 나오는 값 구함 |
| LAST_VALUE(칼럼) | - 파티션에서 가장 나중에 나오는 값 구함 |
| LAG(칼럼, n) | - 칼럼의 n번째 이전 행의 값을 가지고 옴 |
| LEAD(칼럼, n, m) | - n번째 이후 행이 존재하지 않으면 m 출력 |
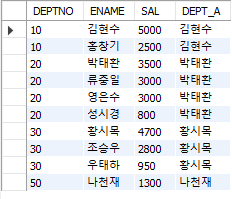
(1) FIRST_VALUE
#행 순서 관련 함수 #FIRST_VALUE SELECT DEPTNO, ENAME, SAL, FIRST_VALUE(ENAME) OVER ( #어떤 칼럼의 첫 행에 오는 사람 이름을 출력해줘 PARTITION BY DEPTNO #그 칼럼은 일단 부서별로 묶은 다음 ORDER BY SAL DESC ROWS UNBOUNDED PRECEDING) #급여를 내림차순으로 정렬한 칼럼이야 DEPT_A FROM EMP;
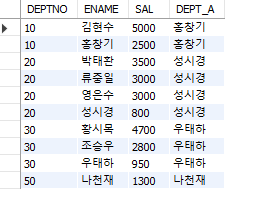
(2) LAST_VALUE
#행 순서 관련 함수 #LAST_VALUE() SELECT DEPTNO, ENAME, SAL, LAST_VALUE(ENAME) OVER ( PARTITION BY DEPTNO ORDER BY SAL DESC ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) DEPT_A FROM EMP;
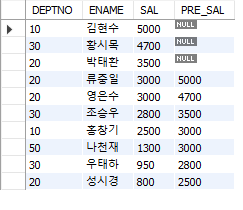
(3) LAG
#행 순서 관련 함수 #LAG() SELECT DEPTNO, ENAME, SAL, LAG(SAL) OVER (ORDER BY SAL DESC)
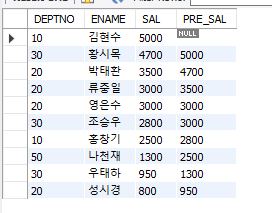
LAG(칼럼, n)으로 n만큼 위에 있는 값을 가져올 수 있다.
#LAG(칼럼, n) SELECT DEPTNO, ENAME, SAL, LAG(SAL,3 ) OVER (ORDER BY SAL DESC) PRE_SAL FROM EMP;
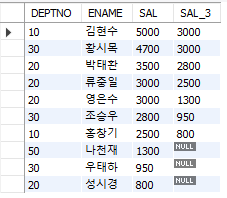
(4) LEAD
#행 순서 관련 함수 #LEAD(칼럼, n) SELECT DEPTNO, ENAME, SAL, LEAD(SAL,3 ) OVER (ORDER BY SAL DESC) SAL_3 FROM EMP;
5. 비율 관련 함수
| 비율 함수 | 설명 |
| CUME_DIST | 누적 백분율 |
| PERCENT_RANK | 순서별 백분율 |
| NTILE(n) | 파티션별로 전체 건수를 n등분했을 때 속하는 값 |
| RATIO_TO_REPORT | 파티션 내에 전체 SUM(칼럼)에 대한 행 별 칼럼값의 백분율을 소수점까지 조회(안 중요) |
#비율 관련 함수 #CUME_DIST(), PERCENT_RANK(), NTILE(n) SELECT DEPTNO, ENAME, SAL, CUME_DIST() OVER (ORDER BY SAL DESC) CUMDIST, PERCENT_RANK() OVER (PARTITION BY DEPTNO ORDER BY SAL DESC) PERCENT_SAL, NTILE(4) OVER (ORDER BY SAL DESC) N_TILE FROM EMP ORDER BY SAL DESC;
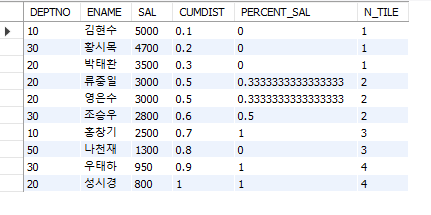
여기서 NTILE에 분배되는 방식이 시험에 출제된 적이 있는데 이해가 쉽도록 예시를 들어보겠다.
데이터가 8개인데 NTILE(4)라면 1, 1, 2, 2, 3, 3, 4, 4 로 분배되고
데이터가 9개인데 NTILE(4)라면 1, 1, 1, 2, 2, 3, 3, 4, 4로
데이터가 10개인데 NTILE(4)라면 1, 1, 1, 2, 2, 2, 3, 3, 4, 4
데이터가 11개인데 NTILE(4)라면 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4
즉, NTILE(n)은 N개의 데이터 n으로 나눴을 때 나오는 몫만큼 공정하게 나눈 다음 발생한 나머지들을 1부터 차례로 다시 부여한다.
6절 테이블 파티션
1. 파티션 기능
- 파티션 : 대용량의 테이블을 여러 데이터 파일에 분리해서 저장하는 것이다.
- 파티션의 기능
- 데이터의 범위를 줄여서 입력, 수정, 삭제, 조회 성능 향상
- 파티션 별로 독립적인 데이터 관리 (파티션 별 백업, 복구 가능/ 파티션 전용 인덱스 생성 가능)
- 파티션은 Oracle 데이터베이스의 논리적 관리 단위인 테이블 스페이스 간 이동이 가능
2. RANGE PARTITION
: 범위를 기준으로 여러 파티션에 나누어 저장 -- ex) 급여를 1000~3000과 3001~5000으로 범위를 나누어 저장
- 날짜, 숫자값으로 분리 가능
- 보관 주기에 따른 삭제 가능
3. LIST PARTITION
: 특정 값을 기준으로 분할 저장 -- ex) 부서번호별로 파티션을 나누어 저장
- 보관 주기에 따른 삭제 불가능
4. HASH PARTITION
: 해시 함수를 사용해 DBMS가 알아서 분할
- 보관 주기에 따른 삭제 가능
4-1. COMPOSITE PARTITION
: 여러 파티션 기벌을 조합해서 사용
5. 파티션 인덱스
| 구분 | 주요 내용 |
| Global Index | 여러 개의 파티션에서 하나의 인덱스를 사용 |
| Local Index | 해당 파티션 별로 각자의 인덱스를 사용 |
| Prefixed Index | 파티션 키와 인덱스키가 동일 |
| Non Prefixed Index | 파티션 키와 인덱스키가 다름 |
드디어 2과목의 2장을 마쳤다.
이번에는 그룹 함수, 순위 함수, 윈도우 함수, 행 순서 함수, 비율 관련 함수와 파티션의 정의 파티션 기법 마지막으로 파티션 인덱스를 배웠다.
다음 장은 마지막 장이며 옵티마이저와 실행계획, 인덱스 등을 배울 것이다.
근데 사실 마지막 3장 내용은 상세한 정의를 알아야 하는 장이지만 SQLD에서는 매우 간단하게 다루는 부분이라 알아도 모호하고 애매하다.
정확하게 알고 싶긴한데 일단 딱 필요한 수준만큼만 공부하자..



