과목 Ⅱ. 데이터모델링의 이해
1장 SQL 기본
5절 WHERE문
1. Where문에 사용하는 연산자
<비교 연산자와 부정 비교 연산자>
| 비교 연산자 | 설명 | 부정 비교 연산자 | 설명 |
| = | 같은 것 조회 | != | 같지 않은 것 조회 |
| < | 작은 것 조회 | ^= | 같지 않은 것 조회 |
| <= | 작거나 같은 것 조회 | <> | 같지 않은 것 조회 |
| > | 큰 것 조회 | Not 칼럼명= | 같지 않은 것 조회 |
| >= | 크거나 같은 것 조회 | Not 칼러명> | 크지 않은 것 조회 |
※ 비교연산자 뒤에는 단일 행 함수가 나와야 함. 만일 다중행 함수(ex. MAX, SUM 등)가 나오면 에러
<논리 연산자>
| 논리 연산자 | 설명 |
| AND | 조건을 모두 만족해야 True |
| OR | 조건 중 하나만 만족해도 True |
| NOT | 참이면 False, 거짓이면 True |
※ 만약 WHERE 구문1 OR 구문2 AND 구문3 이라는 조건이 있다면?
: "구문1"이거나 "구문2이면서 구문3인 것" 조회
<SQL 연산자>
| SQL 연산자 | 설명 |
| LIKE '%비교 문자열%' | 비교 문자열을 조회 ('%'는 모든 값을 의미) |
| BETWEEN A AND B | A와 B 사이의 값 조회 |
| IN(list) | OR을 의미하며 list 값 중 하나만 일치해도 조회됨 |
| IS NULL | NULL값 조회 |
<부정 SQL 연산자>
| 부정 SQL 연산자 | 설명 |
| NOT BETWEEN A AND B | A와 B 사이에 해당하지 않는 값 조회 |
| NOT IN(list) | list와 불일치한 것 조회 |
| IS NOT NULL | NULL값이 아닌 것 조회 |
<연산자 사용 예시>
#비교연산자 사용 예시
select * from emp
where sal>=300; #sal 칼럼이 300이상인 행만 조회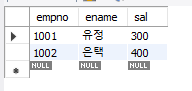
※ WHERE문에 집계함수 사용 불가능
2. Like문 사용
Like문은 와일드카드를 사용해 데이터 조회 가능
WHERE 칼럼 LIKE '문자';
- 와일드카드
- % : 어떤 문자를 포함한 모든 것 조회 -- ex) 조% == '조'로 시작하는 모든 문자 조회
- _ : 한 개인 단일문자 의미 -- ex) 조_ == '조' 뒤에 한 글자만 있는 데이터 조회
만약에 %나 _가 포함된 문자를 조회하고 싶다면?
LIKE '%@%%', LIKE %@_% 처럼 @를 앞에 붙여 ESCAPE해주고 조회
#Like문 사용하기
#와일드카드 %
#'홍'으로 시작하는 모든 문자 조회
select * from emp
where ename like '홍%';
#'정'으로 끝나는 모든 문자 조회
select * from emp
where ename like '%정';
#'은'이 들어가는 모든 문자 조회
select * from emp
where ename like '%은%';
#와일드카드_ 사용
#'홍'으로 시작해 뒤에 한글자만 더 오는 문자 조회
select * from emp
where ename like '홍_';
3. Between문 사용
지정된 범위에 있는 값 조회
#Between문 사용
select * from emp
where sal between 300 and 350; #sal 칼럼에서 300과 350사이인 데이터만 조회
#not between문 사용
select * from emp
where sal not between 300 and 400;

4. IN문 사용
IN문은 OR의 의미를 가지고 있어 리스트 내 하나만 만족해도 조회 가능
#in문 사용
select * from emp
where ename in ('홍설', '홍길동');
#in문 여러 칼럼에 사용
select * from emp
where (ename, sal) in (('홍설','200'),('유정','400')); #괄호를 하나 더 추가해주면 여러 칼럼에 대한 In문 적용됨
5. NULL값 조회
#NULL값 조회
select * from emp
where sal is null;
#IS NOT NULL
select * from emp
where sal is not null;만들어준 emp테이블에는 Null인 행이 없어서 is not null문만 출력됨


<NULL 관련 함수> - 중요!
| NULL 함수 | 설명 |
| NVL 함수 | - NVL(SAL, 0) : SAL 칼럼이 NULL이면 0으로 바꿈 - NULL이 아니면 그대로 |
| NVL2 함수 | - NVL2(SAL, 1, 0) : SAL 칼럼이 NULL이 아니면 1, NULL이면 0으로 반환 |
| NULLIF 함수 | - NULLIF(exp1, exp2) : exp1 = exp2면 NULL을, exp1 != exo2면 exp1 반환 |
| COALESCE 함수 | - COALESCE(exp1, exp2, ... ) : exp들 중에서 NULL이 아닌 첫째 값 반환 |
※ NULL*2 = NULL*3 = NULL*NULL = NULL
※ NULL과 NULL을 비교한 경우는 공집합 (NO ROWS SELECTED)이 출력됨
6절 Group 연산
1. GROUP BY문
테이블에서 소규모 행을 그룹화하여 합계, 평균, 최댓값, 최솟값 등 집계함수를 사용한 계산 가능
먼저 새로운 연산을 위해 새로운 emp 테이블을 만들었다.
##GROUP BY문
#새로운 emp 테이블 생성
create table emp(
empno int(10) primary key,
ename varchar(20),
deptno int(4),
sal int(6));
#새로운 데이터 입력
insert into emp values(100, '김현수', 10, 5000);
insert into emp values(101, '홍창기', 10, 2500);
insert into emp values(102, '박태환', 20, 3500);
insert into emp values(103, '류중일', 20, 5100);
insert into emp values(104, '성시경', 20, 800);
insert into emp values(105, '영은수', 20, 3000);
insert into emp values(106, '조승우', 30, 2800);
insert into emp values(107, '황시목', 30, 4700);
insert into emp values(108, '우태하', 30, 950);
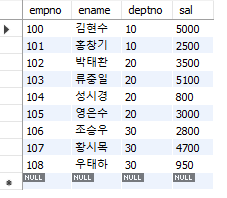
그리고 부서별(deptno별)로 연봉 합계(SUM)를 조회했다.
#GROUP BY문으로 부서별 연봉합 조회
select deptno, sum(sal) from emp #부서번호와, 연봉의 합계를 조회하라
group by deptno; #부서(deptno)별로
<집계 함수 종류>
| 집계 함수 | 설명 |
| COUNT( ) | 행 수 조회 |
| SUM( ) | 합계 조회 |
| AVG( ) | 평균 조회 |
| MAX( ), MIN( ) | 최댓값, 최솟값 조회 |
| STDDEV( ) | 표준편차 조회 |
| VARIAN( ) | 분산 조회 |
| TOP( ) | 카운트가 높은 순으로 출력 |
| WITH TIES | TOP( ) 함수에서 동일한 순위가 있을 경우 함께 출력 |
1-2) COUNT함수에서 NULL값 카운트 여부
COUNT(*)는 NULL값을 세고, COUNT(칼럼)은 NULL값을 세지 않는다.
이를 보여주기 위해 emp 테이블에 mgr 칼럼을 추가했다.
#emp테이블에 mgr 칼럼 추가
alter table emp
add (mgr int(10));
#mgr값 입력
update emp set mgr = 100 where empno = 101;
update emp set mgr = 100 where empno = 102;
update emp set mgr = 101 where empno = 105;
update emp set mgr = 101 where empno = 106;
update emp set mgr = 102 where empno = 107;
update emp set mgr = 102 where empno = 108;
#COUNT(*)와 COUNT(칼럼)
select count(*) from emp; #NULL값을 카운트
select count(mgr) from emp; #NULL값을 세지 않음

count(*), count(칼럼)의 차이를 볼 수 있다.
1-3) GROUP BY문 사용 예제
(1) 부서별, MGR별 급여 평균(sal) 계산
#GROUP BY문 사용예제 1
#부서별, 관리자별 급여평균 계산
select deptno, mgr, avg(sal) from emp #부서, mgr, 급여평균 칼럼을 출력하라
group by deptno, mgr; #부서, mgr별로 묶어서
보면 부서별로 먼저 묶고, 부서별 mgr별로 한 번 더 묶었다.
(2) 부서별 급여합계가 10000이상인 부서만 출력 (HAVING문)
#GROUP BY문 사용예제 2
#부서별 급여합계 중에 급여합계가 10000이상인 부서만 조회
select deptno, sum(sal) from emp
group by deptno
having sum(sal) >= 10000; #Having문을 사용하면 group by문의 결과에 조건을 사용할 수 있다.
HAVING문을 사용하면 GROUP BY문의 결과에 조건을 더해서 사용할 수 있다!
※ HAVING문은 GROUP BY문 없이 혼자 쓰일 수 없음
※ HAVING문에서 집계에 사용한 칼럼은 SELECT로 조회할 수 없음
(3) 사원번호 100~103의 부서별 급여합
#GROUP BY문 사용예제 3
#사원번호 100~103의 부서별 급여 합계 조회
select deptno, sum(sal) from emp
where empno between 100 and 103 #group by문을 쓰기 전에 먼저 where문으로 empno범위를 지정해주기
group by deptno;
7절 SELECT문 실행 순서
SELECT문 실행 순서 문제가 자주 출제된다.
#SELECT문 실행순서
select ename #5
from emp #1
where empno = 10 #2
group by ename #3
having count(*)>=1 #4
order by sal; #6FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
8절 명시적 형변환과 암시적 형변환
- 형변환 : 데이터 타입이 일치하도록 변환하는 것
- 명시적 형변환 : 개발자가 형변환 함수로 데이터 타입을 변환하는 것
- 암시적 형변환 : DBMS에서 자동으로 데이터 타입을 형변환 하는 것
<형변환 함수>
| 형변환 함수 | 설명 |
| TO_NUMBER(문자열) | 문자열->숫자 |
| TO_CHAR(숫자 OR 날짜, [형식]) | 숫자 혹은 날짜 -> [형식]에 맞는 문자열로 변환 |
| TO_DATE(문자열, 형식) | 문자열 -> 형식에 맞는 날짜형 |
※ 인덱스 형변환
- 인덱스 : 데이터를 빠르게 조회하기 위해 인덱스값(INDEX KEY)을 기준으로 정렬한 데이터
기본키에는 자동으로 인덱스가 만들어지고, 이외 칼럼에도 인덱스를 지정해주면 인덱스가 생긴다.
그런 인덱스 칼럼에 형변환이 일어나면 인덱스를 사용할 수 없게 된다.
#자동으로 생성된 인덱스 칼럼에 형변환이 일어나는 경우
select * from emp
where empno = '100';
#emp 테이블에서 empno 칼럼은 기본키여서 인덱스가 자동으로 생성되었고, 숫자형이다.
#여기서 empno = '100'으로 입력한 것은 '100'이라는 문자형을 검색한 것이다.
#이 문제를 해결하기 위해 Oracle에서는 자동적인 형변환, 즉 암시적 형변환이 일어난다.
#empno칼럼이 TO_CHAR(EMPNO)가 되어 문자형으로 변환된다.
#이렇게 인덱스 칼럼이 문자형으로 변환되어 인덱스를 사용할 수 없게 된다.
#이 문제를 해결하기 위해서 우리가 명시적 형변환을 해주어야 한다.
select * from emp
where empno = TO_NUMBER('100');
#이렇게 하면 EMPNO칼럼이 문자형으로 변환되지 않아서 인덱스를 사용할 수 있다.
이렇게 SELECT문에서 사용가능한 WHERE, GROUP BY, HAVING, LIKE문에 대해서 간단히 배웠다.
그리고 SQL문에서 사용하는 각종 연산자들도 배웠다.
다음은 SQL의 내장형 함수들과 DECODE, CASE문, ROWNUM과 WITH문을 배운 다음 조인으로 넘어가자



