과목Ⅰ. 데이터모델링의 이해
2장 데이터 모델과 성능
1절 정규화
1. 정규화(Normalization)
: 데이터의 일관성, 중복 최소화, 데이터 유연성 최대화를 위한 방법 (= 데이터를 분해하는 과정)
- 정규화 수행시 업무에 변화가 발생해도 데이터 모델의 변경을 최소화할 수 있음
<정규화 예시>
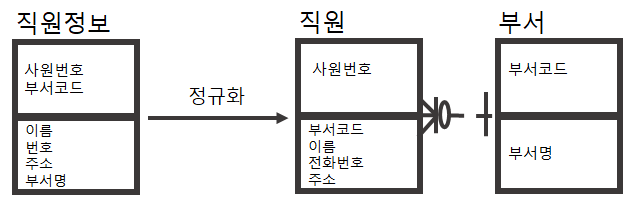
<정규화 절차>
| 정규화 절차 | 설명 |
| 제1정규화 | 기본키 설정 (속성의 원자성 확보 = 속성의 중복값 제거) |
| 제2정규화 | 부분 함수 종속성 제거 (기본키가 2개 이상) |
| 제3정규화 | 이행 함수 종속성 제거 (기본키를 제외한 칼럼 간 종속성 제거) |
| BCNF | 복수의 후보키가 있고 후보키가 복합속성이며, 서로 중첩 |
| 제4정규화 | 다중값 종속성 제거 (안 중요) |
| 제5정규화 | 조인에 의한 종속 분해 (안 중요) |
※ 한 개의 속성으로 유일성이 만족되지 않을 경우, 두 개 속성을 조합해 기본키로 만들기도 함
※ 정규화는 함수적 종속성을 근거로 함
: X가 변할 때 Y도 변화한다면, Y는 X에 함수적으로 종속된다고 말함 (이기적 SQLD 이론서 내용임)
ex) 회원ID가 바뀌면 이름도 바뀜 == 회원ID가 이름을 함수적으로 종속함 == 이름은 회원ID에 함수적으로 종속됨
- 제1정규화
기본키를 설정해준다. (∴ 기본키가 있다면 적어도 1차정규형은 만족)

- 제2정규화
부분 함수 종속성 제거 (복합 인스턴스에 대해 각 인스턴스의 종속성 중복 제거)

- 제3정규화
이행 함수 종속성 제거 (속성 간 종속 제거)
기본키를 제외한 칼럼들 사이에서 함수적 종속성이 발생하는 것을 이행 함수 종속성이라고 한다.
이행 함수 종속성이 발생했을 때 제3정규화를 수행한다.

- BCNF (Boyce-Codd Normal Form)
복수의 후보키가 있고, 후보키들이 복합 속성이면서, 서로 중첩될 때 이를 제거해주는 작업을 BCNF라고 한다.

※ 종속성은 중복으로 판단! X가 같을 때 동일하고, X가 바뀔 때 바뀌는 속성이 종속된 속성임
2절 정규화와 성능
1. 정규화의 문제점
- 데이터 조회 시에 조인을 유발해 CPU와 메모리를 많이 사용
-> 이러한 성능저하를 해결하기 위해 반정규화 사용
3절 반정규화
1. 반정규화
: 데이터 중복을 허용하고 조인을 줄이는 DB성능 향상 방법
-> 조회 속도는 향상 but, 데이터모델의 유연성은 낮아짐 (데이터 변동에 대처를 잘 못하게됨)
∴ 만약, 데이터 무결성(혹은 데이터 유연성)을 원한다면 정규화 수행
데이터 입출력량이 많아서----------┐
경로가 너무 멀어서 조인으로 인한 ├-- 성능 저하가 발생한다면 -> 반정규화 수행!
칼럼을 읽을 때 예상되는 ---------- ┘
2. 반정규화를 수행하는 경우
- 수행 속도가 느려지는 경우
- 다량의 범위를 자주 처리해야 하는 경우
- 특정 범위의 데이터만 자주 처리하는 경우
- 요약/집계 정보가 자주 요구되는 경우
<반정규화 절차>
1) 대상 조사 및 검토
2) 다른 방법 검토 -- ex) 클러스터링, 뷰, 인덱스 튜닝, 파티션 등
3) 반정규화 수행
※ 클러스터링: 인덱스 정보를 저장할 때 물리적으로 정렬해서 저장하는 방법
∴ 조회 시에 인접블록을 연속적으로 읽기 때문에 성능 향상
※ 좋은 모델링의 요건 : 중복 배제, Business Rule, 완전성
3. 반정규화 기법
- 관계의 반정규화 : 모든 속성을 참조하고자 할 때 사용
- 테이블 반정규화 : 데이터 무결성에 영향
- 칼럼 반정규화 : 데이터 무결성에 영향
- 중복 관계 추가 : 데이터 무결성에 영향 없음
| 칼럼의 반정규화 기법 | 내용 |
| 중복 칼럼 추가 | 조인을 감소시키고자 중복된 칼럼 추가 |
| 파생칼럼 추가 | 계산에 의한 성능저하를 예방하고자 미리 값을 계산하여 칼럼(Derived Column)에 보관 |
| 이력테이블 칼럼 추가 | 대량의 이력데이터를 처리할 때, 불특정 날 조회나 최근 값조회 시 발생하는 성능저하를 예방하고자 기능성 칼럼 추가 (ex. 최근값 여부 칼럼, 시작과 종료일자 칼럼 등) |
| 기본키에 의한 칼럼 추가 | 기본키 안에 데이터가 존재하지만 성능향상을 위해 일반속성으로 포함하는 방법 |
| 응용시스템 오작동 처리를 위한 칼럼 추가 | 업무적 의미는 없지만 오작동 처리를 위한 임시적인 기법 |
※(주의) 단순하게 업무처리를 위한 칼럼추가는 반정규화가 아님!
4. 테이블 병합
- 1:1 관계 테이블 병합 -> 성능 향상
- 1:N 관계 테이블 병합 -> 성능 향상 but 데이터 중복 발생 多
- 슈퍼타입과 서브타입 관계 발생할 때 통합 -> 성능 향상
※ 슈퍼타입과 서브타입
: 슈퍼타입은 부모, 서브타입은 자식
ex) 고객 엔터티 = 슈퍼타입
개인고객, 법인고객 = 서브타입
- 슈퍼타입 및 서브타입 변환 방법
- OneToOne Type : 슈퍼타입과 서브타입을 개별 테이블로 도출 -> 테이블 수가 많아 조인 발생多, 관리 어려움
- Plus Type : 슈퍼타입과 서브타입 테이블로 도출 -> 조인 발생 & 관리 어려움
- Single Type : 슈퍼타입과 서브타입을 하나의 테이블로 도출 -> 조인성능 향상 & 관리가 편리 but 입출력 성능 저하
5. 파티션기법
: DB에 파티션을 사용해 테이블을 분할할 수 있음.
파티션을 사용하면 논리적으로는 하나의 테이블이지만 여러 개의 데이터 파일에 분산되어서 저장.
- Range Partition : 데이터 값의 범위를 기준으로 파티션 수행 (날짜, 숫자값으로 분리 / 보관 주기에 따라 테이블의 데이터 쉽게 지우는 것이 가능)
- List Partition : 특정 값을 지정해 파티션 수행 (주기 삭제기능 X)
- Hash Partition : 해시 함수를 적용해 파티션 수행 (지정된 Hash 조건에 따라 테이블 분리 / 주기 삭제 기능 제공)
- Composite Partition : Range, Hash를 복합적으로 사용해 파티션 수행
- 파티션 테이블의 장점
1) 데이터 조회 시 액세스 범위가 줄어들어 성능 향상
2) 데이터가 분할되어 있어 I/O (Input/Output) 성능 향상
3) 각 파티션을 독립적으로 백업 및 복구 가능
4절 분산 데이터베이스
1. 분산 데이터베이스
- 중앙집중형 DB

- 분산 DB
: 물리적으로 떨어진 DB에 네트워크를 연결해서 단일 DB이미지를 보여주고 분산된 작업 처리 수행
-> 고객은 시스템이 네트워크로 분산됐는지 인식 못하고 자신만의 DB를 사용하는 것처럼 사용
-> ∴ 투명성이 중요!
- 분산 DB의 특징 : 지역 자치성, 빠른 응답속도 & 저렴한 통신비용, 오류의 잠재성 높음, 처리비용 높음
<분산 DB의 투명성 종류>
- 분할 투명성 : 고객은 하나의 논리적 릴레이션이 사실 여러 단편으로 분할되어 저장됨을 인식할 필요가 없음
- 위치 투명성 : 고객은 데이터가 어느 위치에 있더라도 동일한 명령을 사용해 접근 가능 = 저장 장소 명시가 불필요
- 지역 사상 투명성 : 각 지역 시스템 이름과 무관한 이름 사용 가능 (위치 투명성과 헷갈리지 말 것!)
- 중복 투명성 : DB 객체가 여러 시스템에 중복되어도 고객과는 무관하게 데이터의 일관성 유지
- 장애 투명성 : 지역 시스템 통신망에 이상이 발생해도 데이터 무결성 보장
- 병행 투명성 : 여러 고객의 응용프로그램이 동시에 분산 DB에 대한 트랜잭션을 수행해도 결과에 이상이 없음
2. 분산 DB 장점과 단점
| 장점 | 단점 |
| - DB 신뢰성, 가용성이 높음 - 병렬처리 수행으로 빠른 응답 - 시스템 용량 확장이 쉬움 - 통신비용이 저렴 |
- 여러 네트워크가 분산되어 관리와 통제가 어려움 - 데이터 무결성 관리의 어려움 (오류 잠재성 높음) - 보안관리 어려움 - DB 설계가 복잡하고 처리비용이 높음 |
※ 데이터 모델의 성능을 고려하는 방법
- 이력 모델 조정, 기본키/외래키 조정, 슈퍼타입/서브타입 조정 등
- DB 용량 산정
- DB의 트랜잭션 유형 파악
'언어 > SQL' 카테고리의 다른 글
| [기본] SQLD 2과목 1장 공부 정리 3 (테이블명 변경, 칼럼 추가/삭제/변경, 테이블 삭제, 뷰 생성/조회/삭제) (0) | 2020.09.02 |
|---|---|
| [기본] SQLD 2과목 1장 공부 정리 2 (DDL문에서 create table, constraint 설정, on delete cascade 옵션) (0) | 2020.09.01 |
| [기초] 사용자 추가, MySQL DB 생성, 사용자 권한 부여 (0) | 2020.09.01 |
| [기본] SQLD 2과목 1장 공부 정리 1 (관계형 DB의 정의, SQL문의 종류, 트랜잭션의 특성) (0) | 2020.09.01 |
| [기본] SQLD 1과목 1장 공부 정리 (데이터모델링, 3층스키마, 엔터티, 속성, 관계, 식별자) (0) | 2020.08.31 |



